Database seeders and scalability
Database seeding is the initial seeding of a database with data.


Most modern frameworks (such as Laravel) have this feature, where the user can programmatically add records to a database.
This is particularly useful because later on, when the system is in production, the database will be populated with information and the service might behave differently with fifty thousand users than it behaved on your development computer, with 3 that you manually added.
But I have found that this is not its biggest strength.
Having a lot of records in your table will easily allow you to spot performance issues early on, while you’re building the app. Whenever I’m working on a new PHP app or just a new table for an existing application, I create a seeder that adds at least 10 thousand records of various types. Then, when I run the unit tests, I’m running them with the TestDox format and verbose flag on, so that I see which tests are slow.
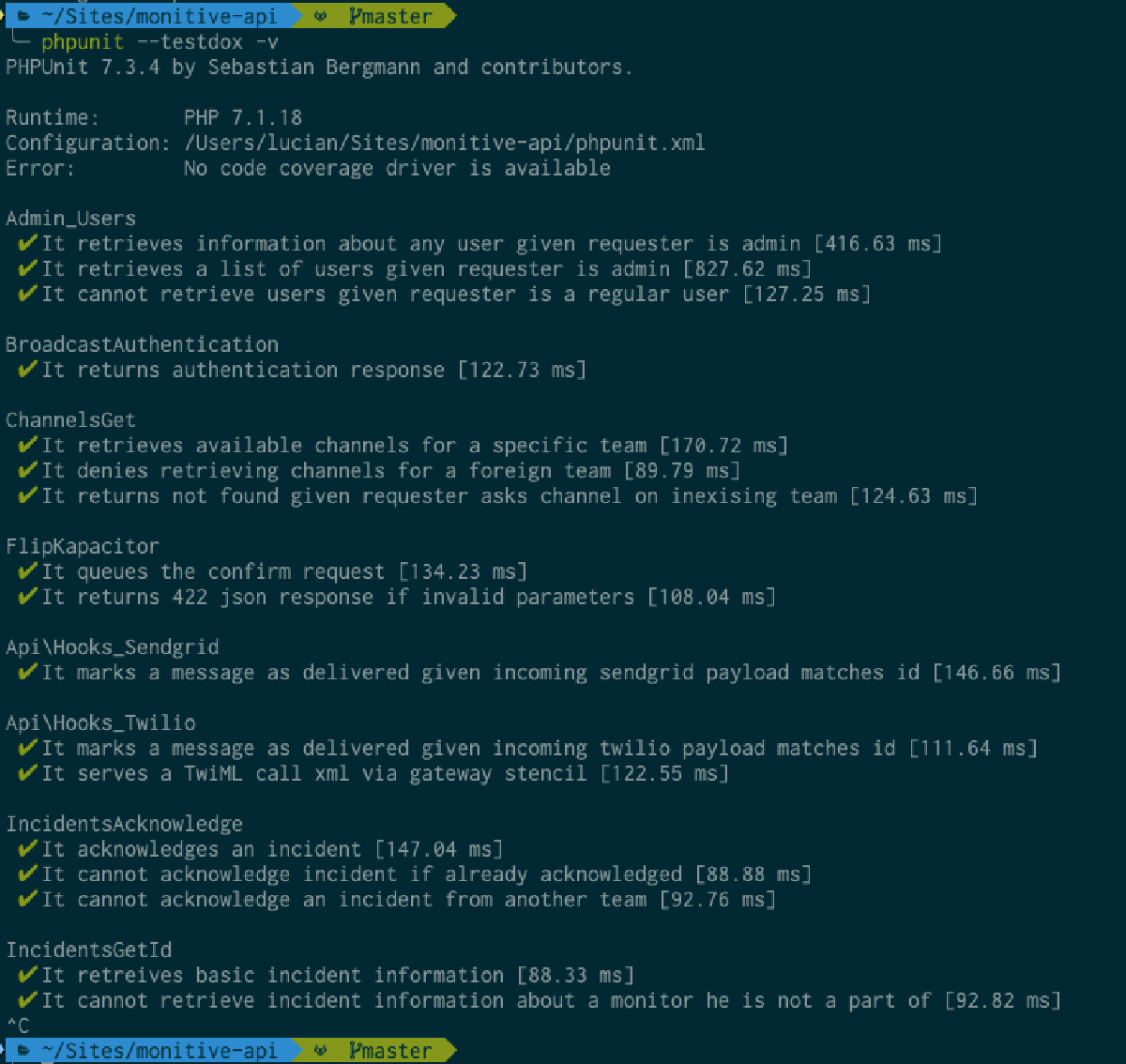
Not only I can immediately see which tests pass, nicely grouped by suite, but for each one I get the time it took to run the test. If at any point a test is taking longer than what is normally acceptable, the timing is displayed in either yellow or red.
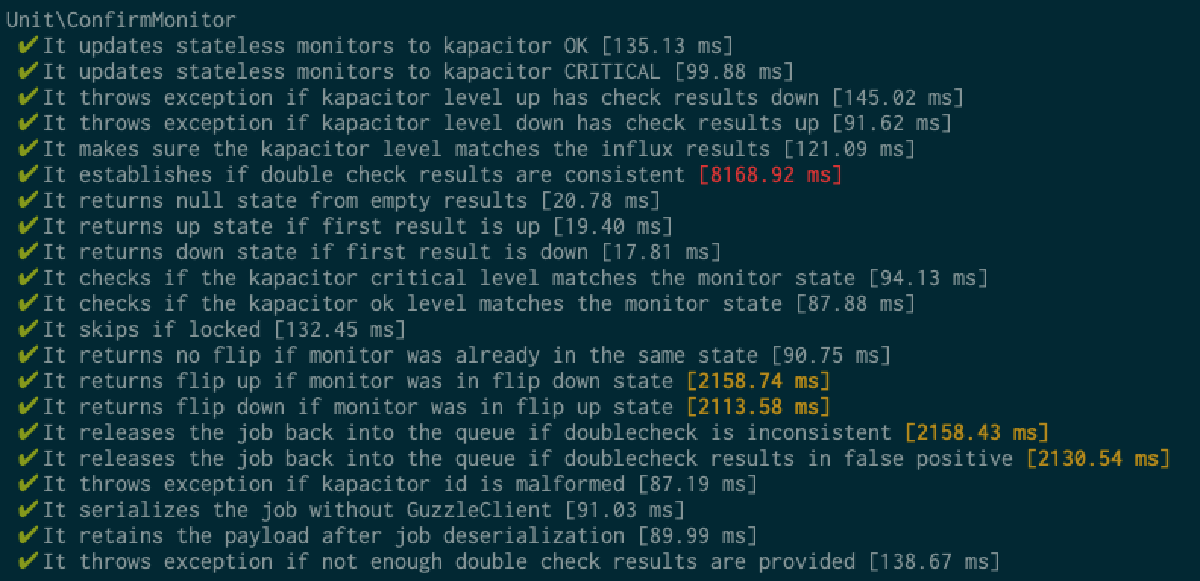
This helps me pinpoint scalability issues really early, before any actual users have ever been in contact with the application.
Of course, longer testing times aren’t only database-related. They can also be caused by actual requests to external resources, signaling that a Guzzle mock or similar is missing.
A note on mocking the Database Layer
Yes, I use the database in my tests, as mocking the database layer brings unnecessary overhead to my productivity. And it also helps detect performance issues by using the seeders to make sure there’s plenty of data in the database.
This allows me to see what indexes are missing. To make sure I don’t mess up the database, I always use DatabaseTransactions to revert all database modifications done by a test.
This doesn’t work in the latest Laravel 5.7 as they seem to have dropped the DatabaseTransactions trait in favor of the RefreshDatabase trait, which is much slower and it basically destroys and rebuilds all your database structures on each test.
Let the planting begin!
As a conclusion, don’t hesitate to create seeds for your system that add a large amount of data, you will end up building a robust, highly efficient system on the very first iteration.
–Photo by Markus Spiske on Unsplash