Check down monitors every minute
When you have the Custom Interval monitoring feature enabled, you can set your monitors to be monitored every 1, 5, 30 minutes or even 6 or 24 hours.

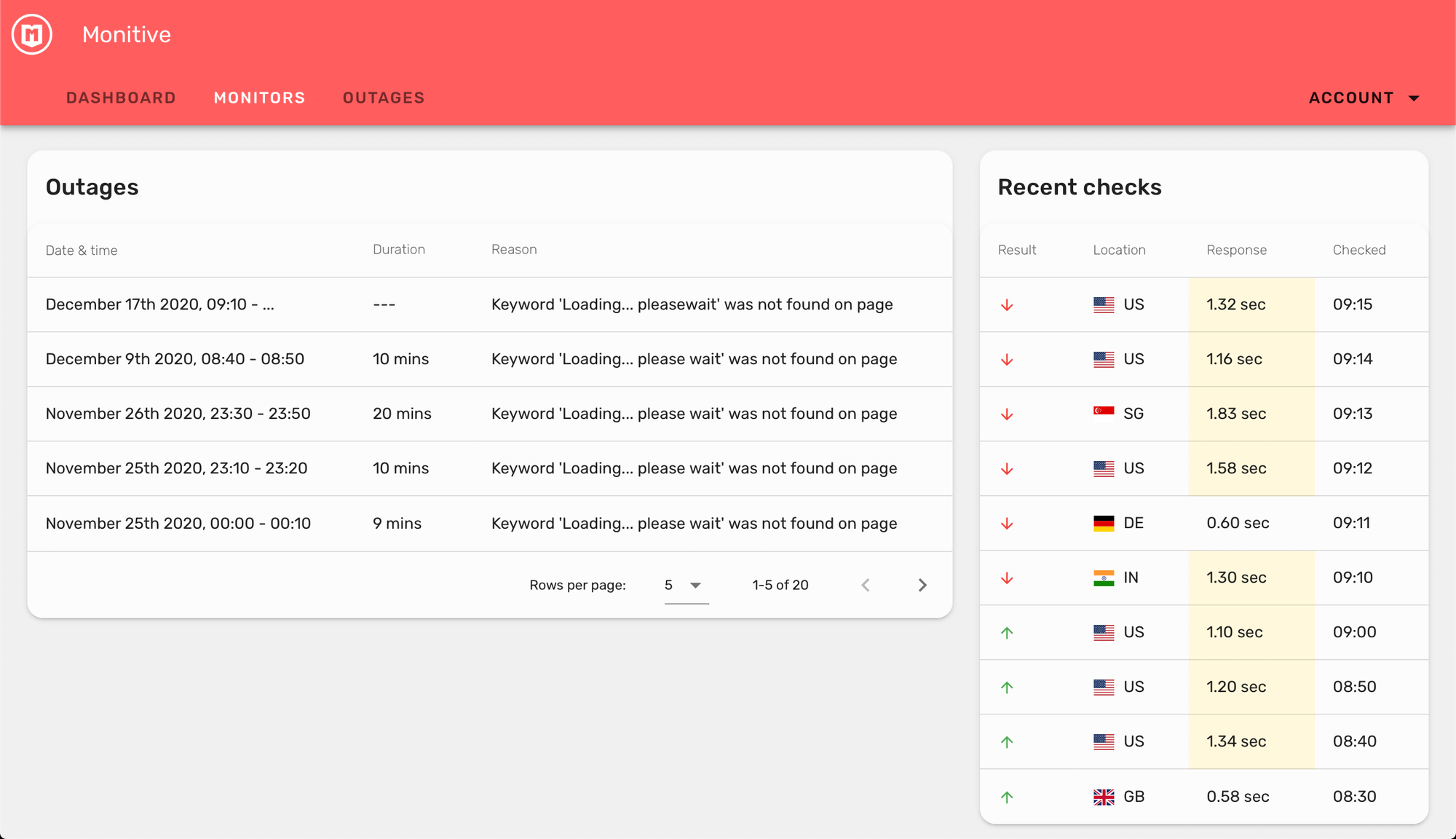
But when such a monitored service goes down, if it’s not checked more often, you were getting inaccurate downtime information.
For example if we’re checking it every 30 minutes, and it goes down, we’ll check back in 30 minutes if it’s back up, even if it might have been just a 2 minutes outage.
We changed this so now when a monitor that has a > 1 minute interval is down, we’re checking it every minute until it’s back up. Then we’ll resume our normal checking schedule.
Other improvements and fixes
- fix: alert rule channel ID validation of string IDs (#299)
- chore: deactivate sending the second email confirmation notification (#307)